TopoLogic — An Interpretable Pipeline for Lane Topology Reasoning
Paper review · improving topology along two tracks — geometric distance and query similarity.
각 figure의 출처는 하이퍼링크로 달아두었습니다 :)
+++ Lane Topology Reasoning 섹션의 세 번째 글이다. TopoNet은 graph로 relation을 reasoning했고, TopoMLP는 “detection만 좋으면 relation은 MLP로 떠먹기”라고 받아쳤다. TopoLogic은 또 다른 각도에서 묻는다 — “MLP가 lane–lane을 그렇게 못 푸는 진짜 이유가, 혹시 lane의 끝점이 살짝 어긋나기(endpoint shift) 때문 아닐까?” 그리고 그 틈을, 학습된 query feature가 아니라 lane의 geometry로 풀 순 없을까?
TopoLogic: An Interpretable Pipeline for Lane Topology Reasoning on Driving Scenes
Authors : Yanping Fu, Wenbin Liao, Xinyuan Liu, Hang Xu, Yike Ma, Feng Dai, Yucheng Zhang (ICT, Chinese Academy of Sciences)
Venue : NeurIPS 2024
Paper Link : https://arxiv.org/abs/2405.14747
Code : https://github.com/Franpin/TopoLogic
Introduction & Motivation
MLP는 왜 lane–lane을 못 풀었나?
앞선 두 글을 떠올려 보자. OpenLane-V2의 네 task 중 유독 lane–lane topology($\text{TOP}_{ll}$)가 바닥을 긴다. TopoNet은 4.1, TopoMLP도 graph를 버리고 올렸다지만 7.2 수준이었다. lane detection($\text{DET}_l$)이 28~30을 찍는 것에 비하면 처참하다. 왜 유독 lane–lane만 이렇게 어려울까?
TopoLogic의 저자들은 그 원인을 endpoint shift에서 찾는다. 두 lane이 이어진다는 건, 한 lane의 끝점과 다음 lane의 시작점이 사실상 같은 자리에 있다는 뜻이다. 그런데 lane은 서로 다른 query에서 독립적으로 regression되므로, 그 두 점이 정확히 겹치도록 보장할 방법이 없다. GT에서는 딱 맞닿아 있던 두 점이, 예측에서는 미묘하게 어긋난다.
문제는 그다음이다. lane query feature를 그냥 MLP에 넣어 0/1을 분류하면, MLP는 이 미묘한 어긋남에 취약하다. 살짝 떨어진 두 끝점을 보고 “연결 안 됨”으로 잘못 분류해 버리기 쉽다. 즉 $\text{TOP}_{ll}$이 낮은 건 reasoning 능력 이전에, endpoint가 흔들리면 MLP의 판단이 같이 흔들리기 때문이라는 게 이 논문의 진단이다.
이 관점에서 저자들이 내놓는 처방은 두 갈래다.
- lane의 geometry를 명시적으로 고려한다. 두 끝점이 “얼마나 가까운가”라는 geometric distance를 explicit하게 계산하고, 그 거리를 learnable한 함수로 topology score에 매핑한다. endpoint가 조금 어긋나도 “충분히 가까우면 연결”로 보는, endpoint shift에 관대한 기준이다.
- 그래도 detection이 틀리면 geometry 자체는 무너질 수밖에 없다. 즉 거리 기반 접근은 lane detection 정확도에 매우 의존한다. 그래서 보완재로, lane query 사이의 semantic similarity(dot product → sigmoid)를 한 갈래 더 둔다.
그리고 이 두 topology를 더해(fuse) 최종 lane–lane topology로 쓴다. 제목의 interpretable은 여기서 온다 — adjacency가 블랙박스 MLP 하나에서 튀어나오는 게 아니라, “끝점이 가까운가(거리)” + “feature가 닮았는가(유사도)”라는 사람이 읽을 수 있는 두 신호의 합이기 때문이다.
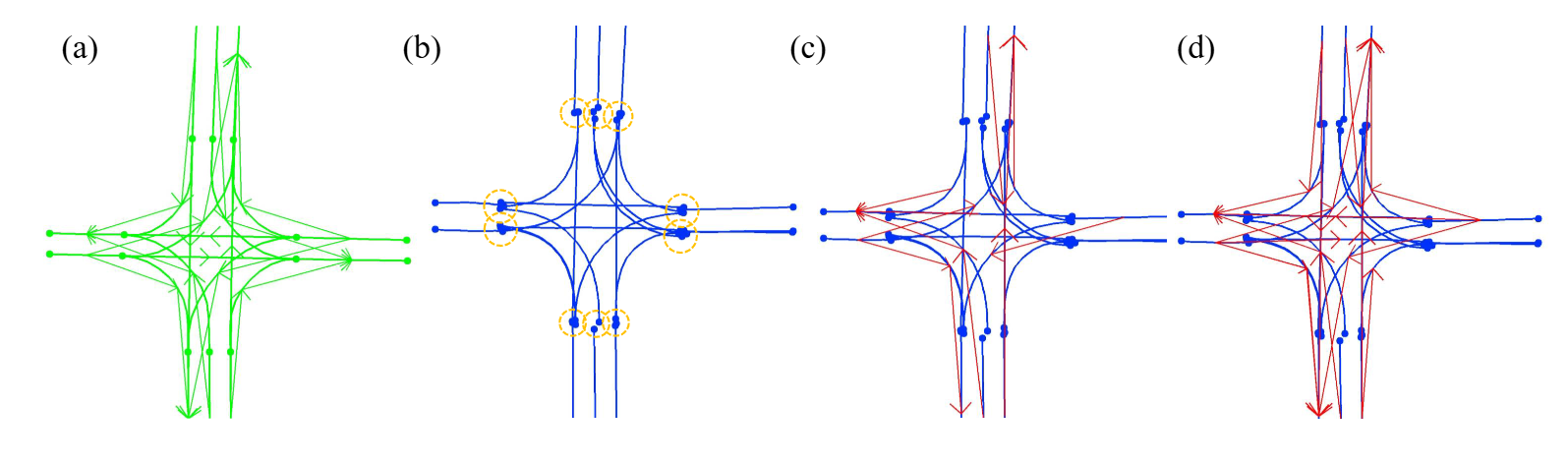
TopoNet·TopoMLP와 무엇이 다른가?
세 모델을 한 줄로 세워 보면 흐름이 또렷하다.
- TopoNet : graph reasoning. lane/traffic query를 node로 보고 SGNN으로 feature를 정제한다. relation은 정제된 feature에서 MLP로 뽑는다.
- TopoMLP : strong detection + simple MLP. detector를 강하게 만들고, relation은 query 짝을 MLP에 한 번 통과시킨다. graph도, residual도 없다.
- TopoLogic : geometry + similarity, 그리고 다시 graph. relation을 MLP feature에만 맡기지 않고, lane의 기하(끝점 거리)를 한 축으로 끌어들인다. 게다가 그렇게 만든 relation을 다시 GNN에 되먹여 다음 layer의 lane feature를 정제한다.
TopoLogic은 TopoNet의 SGNN 구조를 그대로 물려받되(코드도 TopoNet 기반) 그 위에 geometric prior를 추가로 얹었다. TopoMLP가 “graph는 필요 없다”는 쪽으로 갔다면, TopoLogic은 “graph는 두되, 거기에 먹이는 adjacency를 강하게 만들자”는 쪽으로 간 셈이다. 같은 문제를 정반대 방향에서 공략하는 두 후속 논문을 나란히 보는 게 이 시리즈의 재미다.
Method
전체 파이프라인 개요
큰 그림은 TopoNet과 같다. BEV feature를 뽑고, DETR-style decoder로 lane query와 traffic query를 decode하고, 그들 사이 relation을 reasoning한 뒤, 네 출력(lane det, traffic det, lane–lane, lane–traffic)을 낸다.
(사실상 최근 대부분의 자율주행 task가 이렇게 진행하고 있다. BEV Feature를 BEVFormer로 뽑아두고, DETR-style decoder의 query에 deformable cross-attn을 태운 후 task-specific head를 거치는 과정)
TopoLogic이 손대는 곳은 정확히 lane–lane topology를 만드는 방식과, 그것을 decoder layer 사이에서 연결하는 방식이다.
decoder의 한 layer 안에서 벌어지는 일을 순서대로 따라가면 이렇다.
- lane query로 lane 좌표(directed centerline)를 regression한다.
- 그 좌표에서 endpoint 거리 행렬을 만들고, learnable 함수로 distance topology $G_\text{dis}$로 매핑한다.
- 같은 lane query로 similarity topology $G_\text{sim}$을 만든다.
- 둘을 더해 fused adjacency를 만들고, 이를 GNN에 먹여 lane feature를 갱신한다 — 갱신된 feature는 다음 layer로 넘어간다.
아래에서 ②와 ③을 코드와 수식으로 뜯어본 뒤, ④의 fusion을 본다.
① Lane Geometric Distance Topology — 끝점이 가까우면 이어진 것이다
가장 핵심적인 아이디어다. lane query $Q_l$은 lane head를 통해 directed lane line들 $l_0, \dots, l_{n-1}$을 만든다. 두 lane $l_i \to l_j$가 이어지는지는, $l_i$의 끝점과 $l_j$의 시작점이 얼마나 가까운지로 판단한다 (paper Eq. 2–3).
코드도 정확히 이 한 줄이다. lane 좌표를 두 축으로 broadcast한 뒤, $o_1$의 마지막 점([:,:,:,-1,:])과 $o_2$의 첫 점([:,:,:,0,:])의 차이를 좌표축에 대해 절댓값 합한다.
# projects/topologic/models/modules/sgnn_decoder.py — forward()
o1_tensor = coord.detach().unsqueeze(2).repeat(1, 1, num_query, 1, 1)
o2_tensor = coord.detach().unsqueeze(1).repeat(1, num_query, 1, 1, 1)
topo = torch.sum(torch.abs(o1_tensor[:, :, :, -1, :] - o2_tensor[:, :, :, 0, :]), dim=3)
여기서 두 가지를 짚어두자. (1) coord.detach() — 거리 계산에 쓰는 좌표는 detach되어 있다. 즉 distance topology를 통해 흐르는 gradient가 lane 좌표 regression을 직접 흔들지는 않는다. (2) 결과 topo는 $N_l \times N_l$ 행렬로, $(i,j)$ 칸이 곧 $d_{ij}$다.
이제 이 거리를 topology score(0~1)로 바꿔야 한다. 원하는 성질은 분명하다 — 거리가 0에 가까우면(끝점이 겹치면) score가 1에 가깝고, 거리가 멀어지면 score가 0으로 떨어져야 한다. 저자들은 Gaussian에서 영감을 받아 learnable 매핑 함수를 설계한다 (paper Eq. 4).
여기서 $\sigma$는 거리 행렬 $D$의 표준편차(스케일 정규화 역할)이고, $\alpha, \lambda$는 학습되는 파라미터다. 이 함수가 핵심 무기인 이유는 endpoint shift에 대한 관용 때문이다. 논문 Fig. 3에서 $f_\text{ours}$를 Gaussian·sigmoid·tanh 기반 대안과 비교하는데, $f_\text{ours}$는 “연결”로 인정하는 거리 임계가 더 넓다 — 끝점이 조금 어긋나도 여전히 “이어졌다”고 본다.
📐 잠깐! 왜 하필 이 함수꼴인가?
가장 단순한 후보는 그냥 Gaussian $e^{-x^2/2}$이다. 하지만 이건 $x$가 조금만 커져도 score가 급격히 0으로 꺼진다 — 끝점이 살짝만 어긋나도 “끊김”으로 본다는 뜻이라, 정작 고치려던 endpoint shift 문제에 약하다.
$f_\text{ours} = e^{-x^{\alpha}/(\lambda\sigma)}$는 지수의 분모에 $\lambda\sigma$를, 그리고 $x$의 거듭제곱에 $\alpha$를 둬서 곡선의 허리를 데이터에 맞춰 늘릴 수 있다. $\sigma$가 거리 분포의 스케일을 흡수하고, $\lambda$가 그 위에서 “얼마나 너그럽게 볼지”를, $\alpha$가 곡선이 꺼지는 모양을 학습으로 조절한다. 그 결과 임계 거리가 Gaussian보다 넓어져, 같은 endpoint shift에도 더 자주 “연결”로 판정한다. 논문 Table 3의 ablation도 $f_\text{ours}$가 sigmoid 기반보다 OLS 41.4 → 44.1로 앞선다는 걸 보여준다.
🤔 (사견) 이게 정말 “learnable”이라 부를 만한가? 개인적으로 한 가지 걸리는 게 있다. $\alpha, \lambda$가
nn.Parameter인 건 맞지만, 이 둘에 직접 걸리는 loss나 regularization이 없다. 코드를 따라가 보면 $\alpha, \lambda$($=$self.P, self.w)는 오직 distance topology → fusion → GNN → 최종 lane loss로 간접적으로만 gradient를 받는데, 그나마도 distance 쪽은 좌표를detach하고 fusion에서 similarity도detach해서 신호가 더 가늘다. 게다가 optimizer엔weight_decay=0.01이 걸려 있고 이 1×1 스칼라들을 따로 제외하지도 않으니, 오히려 값을 0쪽으로 당기는 압력만 명시적으로 존재하는 셈이다. 그래서 나는 이 파라미터들이 사실상 초기값에 크게 좌우되는 hyperparameter에 가깝다고 본다. 실제로 논문과 코드의 초기값부터 어긋난다 — 논문은 $\alpha=0.2, \lambda=2$로 초기화한다는데, 코드는P=2, w=10이다(같은 $\alpha$라면 10배 차이다).글을 쓰고 나서 OpenReview를 찾아보니, NeurIPS 리뷰어 두 명이 정확히 같은 지점을 짚었다. 한 리뷰어는 “learnable mapping이 다른 함수보다 threshold가 훨씬 높으니, 차라리 hyperparameter를 여러 값으로 hand-tuning해 그 효과를 보는 게 낫겠다”고 했고, 다른 리뷰어는 더 직접적으로 ”$f_\text{ours}$는 결국 decision boundary만 조정한 Gaussian일 뿐이라, 공정한 비교라면 hand-tuned boundary와 비교해야 한다”고 적었다. 내가 의심한 “사실상 상수 아니냐”가 리뷰 단계에서 이미 두 번 나온 것이다.
그래서 저자는 그 요구에 응해 실제로 sensitivity 실험을 했다. rebuttal에서 $\alpha, \lambda$를 격자로 바꿔가며 TOP$_{ll}$을 잰 표를 내놨는데, 결과가 이 의심을 정확하게 드러낸다 — $\alpha$를 2.0에서 1.3으로 손으로 옮기는 것만으로 TOP$_{ll}$이 20.4 → 23.9로 +3.5나 움직였고, 최적은 $\alpha=1.3, \lambda=0.23$이었다. 그런데 이 값은 논문 본문이 적은 초기값($\alpha=0.2, \lambda=2$)과도, 코드 초기값($P=2, w=10$)과도 전혀 다르다. 더 결정적으로, 이 표가 보여주는 건 “hand-tuned로 23.9를 그대로 얻을 수 있다”이지, “learnable이 fixed보다 낫다”가 아니다. 즉 리뷰어 요구로 돌린 그 실험이, 역설적으로 learnability가 굳이 필요하지 않다는 의심을 뒷받침하는 그림이 돼버렸다 — 저자도 “원래 결과와 일치한다”고만 했지, learnable이 더 높다고는 끝내 말하지 못했다. (다른 리뷰어와의 논의에선 “TOP$_{ll}$이 hyperparameter에 민감한 건 맞다”며 민감성 자체를 인정하기도 했다.)
정리하면 두 가지다. 첫째, 이 sweep 표는 rebuttal에만 있고 camera-ready 본문엔 끝내 들어가지 않았다 — 논문만 읽는 독자는 이 민감성을 볼 수 없고, 본문엔 여전히 “$\alpha=0.2$로 초기화”만 적혀 있다. 저자 본인도 껄끄러운 부분이라 안 넣은 것 같은데, 적어도 언급은 해줘야 하지 않았을까? 둘째, 그래서 “learnable mapping function”이라는 셀링포인트는, 정작 그 learnability가 fixed보다 낫다는 증거가 하나도 없다. (아니 본인이 설계한 learnable parameter의 initial 초기값에 대한 sensitivity는 당연히 들어가야 하는거 아닌가? 다른 곳도 아니고 근본이 ML인 학회인데… 내가 리뷰어라면 이것만으로 좋은 점수를 주진 못했을 것 같다.) 함수의 형태가 endpoint shift에 강하다는 것(Table 3)과, 그 안의 파라미터가 학습으로 좋아진다는 것은 별개의 주장인데, 결국 전자만 입증된 셈이다.
그래서 distance topology는 (paper Eq. 5):
코드에서 이 매핑은 한 줄이다. 그리고 self-loop 제거를 위해 대각선을 0으로 만드는 topo_mask(= $1 - I$)를 곱한다 — lane이 자기 자신과 이어진다고 보면 안 되니까.
# projects/topologic/models/modules/sgnn_decoder.py — forward()
topo_mask = 1 - torch.eye(num_query, device=topo.device)
sigma = torch.std(topo)
topo = torch.exp(-torch.pow(topo, self.P) / (self.w)) * topo_mask
여기서 코드와 수식의 대응을 정확히 맞춰두자. 논문의 $\alpha$는 코드의 self.P이고, 논문의 $\lambda\sigma$ 자리에는 코드에서 learnable scalar self.w 하나가 들어간다. 둘 다 nn.Parameter로, decoder 생성자에서 초기화된다.
# projects/topologic/models/modules/sgnn_decoder.py — __init__()
self.w = nn.Parameter(torch.tensor([10], dtype=torch.float32))
self.P = nn.Parameter(torch.tensor([2], dtype=torch.float32))
self.lamda_1 = nn.Parameter(torch.tensor([1], dtype=torch.float32))
self.lamda_2 = nn.Parameter(torch.tensor([1], dtype=torch.float32))
⚠️ 수식과 코드의 미묘한 간극. 논문 Eq. 4는 분모를 $\lambda \cdot \sigma$로 적어 $\sigma$(거리 행렬의 표준편차)가 매 forward마다 곱해지는 것처럼 읽힌다. 하지만 실제 학습 코드(
sgnn_decoder.py)는 분모에 learnable scalarself.w하나만 쓴다.sigma = torch.std(topo)가 계산은 되지만 정작 지수식에는 들어가지 않는다(주석 디버그용에 가깝다). 즉 ”$\lambda\sigma$“가 코드에서는 단일 학습 파라미터 $w$로 흡수된 형태다. 재현할 때 이 점을 모르면 수식 그대로 $\sigma$를 곱했다가 결과가 어긋날 수 있다. (이 논문이 점점 신뢰되지 않는다…)
② Lane Similarity Topology — feature가 닮았으면 이어진 것이다
거리 기반 접근에는 분명한 약점이 있다. lane detection이 틀리면(끝점 좌표 자체가 엉뚱하면), 거리도 같이 엉뚱해진다. 그래서 저자들은 좌표가 아니라 query feature를 보는 두 번째 갈래를 둔다 — 두 lane query가 high-dimensional space에서 얼마나 닮았는지로 연결을 점친다.
방식은 단순하다. lane query $Q_l$을 서로 다른 두 MLP로 임베딩한 뒤, 내적(matmul)해서 similarity를 만들고, sigmoid로 0~1사이에 mapping한다 (paper Eq. 7–9).
코드의 similarity head가 이걸 그대로 구현한다. 흥미로운 건 TopoMLP의 topology head와의 차이다. TopoMLP는 두 query 임베딩을 concat해서 또 다른 MLP(classifier)로 logit을 뽑았다. TopoLogic은 concat·classifier 없이, 두 임베딩의 내적을 곧장 logit으로 쓴다. 그래서 classifier가 코드에서 아예 주석처리되어 있다.
# projects/topologic/models/dense_heads/relationship_head.py
class SingleLayerRelationshipHead(nn.Module):
def __init__(self, in_channels_o1, in_channels_o2=None, shared_param=True, ...):
self.MLP_o1 = MLP(in_channels_o1, in_channels_o1, 256, 3)
if shared_param:
self.MLP_o2 = self.MLP_o1
else:
self.MLP_o2 = MLP(in_channels_o2, in_channels_o2, 256, 3)
# self.classifier = MLP(256, 256, 1, 3) # ← TopoMLP와 달리 쓰지 않는다
def forward(self, o1_feats, o2_feats):
o1_embeds = self.MLP_o1(o1_feats)
o2_embeds = self.MLP_o2(o2_feats)
o2_embeds = o2_embeds.permute(0, 2, 1)
relationship_pred = torch.matmul(o1_embeds, o2_embeds).unsqueeze(-1) # 내적이 곧 logit
return relationship_pred
즉 lane–lane similarity head는 $N_l \times N_l$ 짝마다 내적값 하나(logit)를 내놓고, 거기에 sigmoid를 씌우면 $G_\text{sim}$이 된다. (참고로 클래스의 기본 인자는 shared_param=True지만 — 두 입력이 같은 lane query set이니 임베딩 MLP를 공유해도 자연스럽다 — 실제 subset-A config는 shared_param=False로 두 MLP를 따로 둔다. 앞 글에서 강조한 “default와 config 값이 다른” 패턴이 여기서도 반복된다.)
③ Fusion — 두 topology를 더하고, 다시 GNN에 먹인다
이제 두 갈래가 만난다. distance topology $G_\text{dis}$와 similarity topology $G_\text{sim}$을 learnable 가중치로 더해 최종 lane–lane adjacency를 만든다. 그리고 — 이게 TopoMLP와 결정적으로 갈리는 지점인데 — 그 adjacency를 다음 decoder layer의 GNN 입력으로 되먹인다.
# projects/topologic/models/modules/sgnn_decoder.py — forward() (decoder layer 내부)
lclc_rel_out = lclc_branches[lid](output, output) # similarity branch (내적 logit)
lclc_rel_adj = lclc_rel_out.squeeze(-1).sigmoid() # G_sim
prev_lclc_adj = self.lamda_1 * lclc_rel_adj.detach() + self.lamda_2 * topo # G_sim + G_dis
여기서 topo는 ①에서 만든 $G_\text{dis}$이고, lclc_rel_adj는 ②의 $G_\text{sim}$이다. 둘을 $\lambda_1, \lambda_2$로 가중합한 prev_lclc_adj가 fused topology다. 이 텐서는 루프의 다음 iteration에서 lclc_adj=prev_lclc_adj로 layer에 들어가, GNN(graph convolution)이 이어진 이웃 lane의 feature를 모아 현재 lane feature를 갱신하는 데 쓰인다.
이 한 줄에 TopoLogic의 철학이 응축돼 있다.
- $G_\text{sim}$에는
.detach()가 붙는다. similarity가 만든 adjacency가 GNN을 통해 lane feature를 정제하긴 하지만, “GNN을 거친 결과”의 gradient가 다시 similarity head로 역류하지는 않게 끊은 것이다. ($G_\text{dis}$ 쪽은 애초에 ①에서 좌표를 detach했으니 자연히 끊겨 있다.) - 그럼에도 두 branch는 각자 직접 loss를 받는다. fusion으로 feature를 정제하는 경로와, topology 자체를 학습시키는 경로가 분리돼 있다.
- distance가 graph에 직접 들어간다. TopoNet의 SGNN은 학습된 feature로만 adjacency를 추정했지만, TopoLogic의 GNN은 “끝점이 실제로 가까운가”라는 기하 신호를 adjacency에 직접 받는다. graph reasoning에 기하 prior를 주입한 셈이다.
📌 training과 inference의 fusion이 미묘하게 다르다. 위는 decoder 내부(training 경로)의 fusion이고, learnable
self.P / self.w / self.lamda_*를 쓴다. 반면 최종 예측을 뽑는 inference 경로(topologic_head.py의get_lanes())에서는 같은 fusion을 하되 이 값들이 상수로 하드코딩되어 있다 —P=2, w=11.5275, lamda_1=lamda_2=1. 즉 학습이 끝난 시점의 파라미터(특히 $w$가 초기값 10에서 11.5275 부근으로 수렴)를 코드에 박아둔 것이다. 재현 시에는 학습된 checkpoint의 실제 값과 이 하드코딩이 일치하는지 확인하는 게 안전하다. (할많하않)
# projects/topologic/models/dense_heads/topologic_head.py — get_lanes() (inference)
P, w = 2, 11.5275
lamda_1, lamda_2 = 1, 1
topo = torch.exp(-torch.pow(topo, P) / (w)) * topo_mask # G_dis (학습된 상수로)
distance_topo = topo.detach().cpu().numpy()
Sim_topo = preds_dicts['all_lclc_preds'][-1].squeeze(-1).sigmoid().detach().cpu().numpy()
all_lclc_preds = lamda_1 * Sim_topo + lamda_2 * distance_topo # 최종 lane–lane topology
④ Loss — TopoNet 계보 그대로
relation loss 자체는 새로울 게 없다. detection의 Hungarian matching으로 GT를 잡은 query만 골라 그 사이에 GT adjacency를 깔고, 연결된 pair가 극소수인 sparse graph라 Focal Loss($\gamma=2.0, \alpha=0.25$)로 imbalance를 누른다. TopoNet·TopoMLP에서 본 그 메커니즘 그대로다. lane–lane loss는 similarity branch의 logit(lclc_rel_out)에 걸리고, SGNN을 쓰므로 매 decoder layer마다 걸려 layer를 거치며 정제된다(이 점은 TopoMLP가 최종 logit 한 번에만 걸던 것과 다르고, TopoNet과 같다). 자세한 흐름은 TopoNet 글의 Topology Loss에서 다뤘으니 넘어간다.
OpenLane-V2 Benchmark & Results
평가 benchmark·metric은 앞 두 글과 동일한 OpenLane-V2, OLS다.
여기서부터가 중요하다. TopoMLP 글에서 짚었듯 OpenLane-V2의 TOP metric은 v1.0.0 → v2.1.0으로 정의가 한 번 바뀌었고, 같은 모델이라도 버전이 다르면 $\text{TOP}_{ll}$ 숫자가 크게 달라진다. TopoLogic 논문은 두 버전을 모두 표에 병기한다 — 앞 글의 경고를 정확히 의식한 셈이다. subset-A 기준, paper Table 1의 수치다.
| Method | $\text{DET}_l$ | $\text{DET}_t$ | $\text{TOP}_{ll}$ (v1.0.0) | $\text{TOP}_{ll}$ (v2.1.0) | OLS (v1.0.0) | OLS (v2.1.0) |
|---|---|---|---|---|---|---|
| TopoNet | 28.6 | 48.6 | 4.1 | 10.9 | 35.6 | 39.8 |
| TopoLogic | 29.9 | 47.2 | 18.6 | 23.9 | 41.6 | 44.1 |
읽는 법은 이렇다.
- detection은 비등하다. $\text{DET}_l$ 28.6 → 29.9로 살짝 높지만, 격차의 본진은 거기가 아니다.
- $\text{TOP}_{ll}$이 폭발한다. v1.0.0에서 4.1 → 18.6, v2.1.0에서 10.9 → 23.9. detection이 거의 같은데 lane–lane topology만 두 배 이상이다 — endpoint shift를 기하로 흡수한 효과가 그대로 드러나는 대목이다.
- 그 결과 OLS가 v2.1.0 기준 39.8 → 44.1로 올라선다. (abstract가 내세우는 “23.9 v.s. 10.9, 44.1 v.s. 39.8”이 바로 이 v2.1.0 수치다.)
⚠️ 버전 교차 비교 금지 (다시). 위 표의 v1.0.0 열과 v2.1.0 열을 섞어 읽으면 안 된다. 그리고 TopoMLP 글의 표(대부분 v1.0.0 기준 OLS 38.2 등)와 이 글의 v2.1.0 수치를 나란히 두고 “TopoLogic이 TopoMLP보다 몇 점 높다”고 단정하는 것도 위험하다 — 같은 버전끼리만 비교해야 한다.
번외 — 학습 없이 끼우기만 해도 오른다 (plug-in)
TopoLogic의 가장 실용적인 주장은 따로 있다. geometric distance 접근은 모델 구조에 묶여 있지 않으므로, 이미 학습이 끝난 다른 모델 위에 후처리(post-processing)로 그냥 얹을 수 있다. 재학습 없이, inference 단계에서 끝점 거리로 만든 $G_\text{dis}$를 기존 모델의 topology에 더하기만 하면 된다.
논문 Table 5(와 Fig. 1)가 이걸 보여준다. 잘 학습된 모델들에 geometric distance를 후처리로만 끼웠을 때(+GeoDist) $\text{TOP}_{ll}$이 일제히 오른다 — TopoNet 10.9 → 22.3, SMERF(SDMap) 15.4 → 26.2, LaneSegNet(lane segment) 25.4 → 29.6. 재학습은 한 줄도 없다. “기하는 학습된 weight 바깥에 있는 공짜 신호”라는 이 논문의 관점이, 가장 직접적으로 드러나는 실험이다.
이 plug-in 성질은 TopoMLP의 thesis와 묘하게 공명한다. TopoMLP가 “topology의 천장은 detection이 정한다”고 했다면, TopoLogic은 거기에 “그 detection 결과(끝점 좌표)를 한 번 더 짜내면, 학습 없이도 topology를 더 올릴 여지가 있다“를 더한 셈이다.
Conclusion — geometry를 topology로
정리하면, TopoLogic의 기여는 이렇다.
lane–lane topology가 낮은 건 reasoning 이전에 endpoint shift 탓이 크다. 그러니 학습된 feature에만 맡기지 말고, 끝점 거리라는 geometry 신호를 learnable 함수로 topology에 직접 넣어라 — 그리고 그것을 다시 GNN에 태워라.
TopoNet이 문제(end-to-end topology)를 정의하고, TopoMLP가 “bottleneck은 detection”이라 답했다면, TopoLogic은 그 bottleneck을 한 겹 더 들춰 “detection이 만든 끝점이 어긋나는 것까지가 진짜 병목”이라 짚고, 그 틈을 기하로 메운다. 세 논문이 같은 $\text{TOP}_{ll}$이라는 한 숫자를 서로 다른 각도에서 공략하는 그림이 이제 꽤 선명하다.
다만 두 가지는 짚고 가야 한다. 첫째, 앞서 본 대로 수식(Eq. 4의 $\lambda\sigma$)과 코드(단일 learnable $w$)에 간극이 있고, training fusion(learnable)과 inference fusion(하드코딩된 상수)도 다르다 — 재현 시 코드를 직접 확인해야 한다. 둘째, geometric distance가 강력한 만큼 lane detection 품질에 더 민감해진다는 양날의 검도 있다(그래서 similarity branch가 보완재로 필요하다).
그럼에도 “interpretable한 두 신호의 합 + geometry의 graph 재사용”이라는 설계는 그리 나쁘지않다. 정교하게 설계된 논문은 아니어도, 얼마 없는 Lane Topology Reasoning에 단비같은 논문이긴 하다. (AC가 최종판단을 내릴 때도 이런 점을 매우 고려한듯 한 것이 메타리뷰에 드러나있다.)
읽어주셔서 감사합니다. 혹시 제가 잘못 이해한 부분이 있다면 언제든 알려주세요 :)
Figure sources are linked inline :)
+++ Third post in the Lane Topology Reasoning section. TopoNet reasoned over relations with a graph; TopoMLP countered that “if detection is good, an MLP spoon-feeds the relation.” TopoLogic asks from yet another angle — “is the real reason an MLP struggles with lane–lane that the lane endpoints are slightly off (endpoint shift)?” — and fills that gap not with learned query features but with the geometry of the lanes themselves. 🚀
TopoLogic: An Interpretable Pipeline for Lane Topology Reasoning on Driving Scenes
Authors : Yanping Fu, Wenbin Liao, Xinyuan Liu, Hang Xu, Yike Ma, Feng Dai, Yucheng Zhang (ICT, Chinese Academy of Sciences)
Venue : NeurIPS 2024
Paper Link : https://arxiv.org/abs/2405.14747
Code : https://github.com/Franpin/TopoLogic
Introduction & Motivation
Why did the MLP fail at lane–lane?
Recall the previous two posts. Of OpenLane-V2’s four tasks, lane–lane topology ($\text{TOP}_{ll}$) crawls along the floor: 4.1 for TopoNet, and even TopoMLP — which dropped the graph to push it up — only reached about 7.2. Against lane detection ($\text{DET}_l$) sitting at 28–30, that’s dismal. Why is lane–lane alone this hard?
The authors trace it to endpoint shift. Two lanes being connected means the end of one lane and the start of the next sit at essentially the same spot. But lanes are regressed independently from different queries, so there is no guarantee those two points coincide exactly. Points that touched perfectly in the GT come out slightly misaligned in the prediction.
The trouble is what comes next. Feed the lane query features straight into an MLP to classify 0/1, and the MLP is fragile to this slight misalignment. Seeing two endpoints that fall a little apart, it readily misclassifies them as “not connected.” So a low $\text{TOP}_{ll}$ is, before any question of reasoning power, a matter of the MLP’s verdict wobbling whenever the endpoints wobble — that is the paper’s diagnosis.
From this viewpoint the prescription is twofold.
- Look at the lane’s geometry directly. Explicitly compute the geometric distance — “how close are the two endpoints” — and map that distance to a topology score through a learnable function. It’s a criterion tolerant of endpoint shift: even if the endpoints are a bit off, “close enough” still counts as connected.
- But if detection is wrong, the geometry collapses. The distance-based approach depends wholly on lane detection accuracy. So as a complement, add one more branch: the semantic similarity between lane queries (dot product → sigmoid).
These two topologies are then fused into the final lane–lane topology. The title’s interpretable comes from here — the adjacency is not spat out by one black-box MLP, but is the sum of two human-readable signals: “are the endpoints close (distance)” + “are the features alike (similarity).”
What differs from TopoNet / TopoMLP?
Line the three up and the trajectory is clear.
- TopoNet : graph reasoning. Lane/traffic queries are nodes; an SGNN refines the features. The relation is read off the refined features with an MLP.
- TopoMLP : strong detection + simple MLP. Make the detector strong; predict the relation by pushing query pairs through an MLP once. No graph, no feedback.
- TopoLogic : geometry + similarity, then graph again. Don’t leave the relation to MLP features alone — pull in the lane’s geometry (endpoint distance) as one axis. And feed that relation back into a GNN to refine the next layer’s lane features.
What’s interesting is that TopoLogic inherits TopoNet’s SGNN structure as-is (the code is built on TopoNet too) and mounts the geometric prior on top. Where TopoMLP went the “no graph needed” route, TopoLogic went the “keep the graph, but make the adjacency you feed it smarter” route. Reading two successor papers that attack the same problem from opposite directions side by side is the fun of this series.
Method
Pipeline overview
The big picture matches TopoNet. Extract BEV features, decode lane and traffic queries with a DETR-style decoder, reason the relations among them, and produce four outputs (lane det, traffic det, lane–lane, lane–traffic).
(This is, in fact, how most recent autonomous-driving tasks proceed: pull BEV features with BEVFormer, run the DETR-style decoder’s queries through deformable cross-attention, then pass them to task-specific heads.)
What TopoLogic touches is precisely how the lane–lane topology is produced and how it is wired between decoder layers.
Trace what happens inside one decoder layer, in order:
- Regress lane coordinates (directed centerlines) from the lane queries.
- Build an endpoint distance matrix from those coordinates and map it, via a learnable function, into a distance topology $G_\text{dis}$.
- Build a similarity topology $G_\text{sim}$ from the same lane queries.
- Add the two into a fused adjacency and feed it into the GNN to update the lane features — which pass to the next layer.
Below we dissect ② and ③ with code and math, then look at the fusion in ④.
① Lane Geometric Distance Topology — close endpoints mean a connection
This is the core idea. The lane query $Q_l$ produces directed lane lines $l_0, \dots, l_{n-1}$ via the lane head. Whether $l_i \to l_j$ connect is judged by how close $l_i$’s endpoint is to $l_j$’s start point (paper Eq. 2–3).
The code is exactly this one line. Broadcast the lane coordinates along two axes, then take the absolute difference between $o_1$’s last point ([:,:,:,-1,:]) and $o_2$’s first point ([:,:,:,0,:]), summed over the coordinate axes.
# projects/topologic/models/modules/sgnn_decoder.py — forward()
o1_tensor = coord.detach().unsqueeze(2).repeat(1, 1, num_query, 1, 1)
o2_tensor = coord.detach().unsqueeze(1).repeat(1, num_query, 1, 1, 1)
topo = torch.sum(torch.abs(o1_tensor[:, :, :, -1, :] - o2_tensor[:, :, :, 0, :]), dim=3)
Two things to note. (1) coord.detach() — the coordinates used for the distance are detached, so the gradient flowing through the distance topology does not directly perturb lane coordinate regression. (2) The result topo is an $N_l \times N_l$ matrix whose $(i,j)$ cell is $d_{ij}$.
Now this distance must become a topology score (0–1). The desired behavior is clear — when the distance is near 0 (endpoints overlap) the score should be near 1, and as the distance grows the score should fall toward 0. Inspired by the Gaussian, the authors design a learnable mapping function (paper Eq. 4).
Here $\sigma$ is the standard deviation of the distance matrix $D$ (a scale-normalizer), and $\alpha, \lambda$ are learnable parameters. This function is the key weapon because of its tolerance to endpoint shift. In Fig. 3 the paper compares $f_\text{ours}$ with Gaussian/sigmoid/tanh-based alternatives, and $f_\text{ours}$ admits a wider distance threshold for “connected” — even with the endpoints somewhat off, it still reads them as joined.
📐 A quick aside — why this functional form?
The simplest candidate is a plain Gaussian $e^{-x^2/2}$. But its score collapses to 0 the moment $x$ grows even slightly — meaning a tiny endpoint shift reads as “disconnected,” which is weak at exactly the endpoint-shift problem it was meant to fix.
$f_\text{ours} = e^{-x^{\alpha}/(\lambda\sigma)}$ puts $\lambda\sigma$ in the exponent’s denominator and $\alpha$ on the power of $x$, letting the waist of the curve stretch to fit the data. $\sigma$ absorbs the scale of the distance distribution, $\lambda$ sets “how generously to read it,” and $\alpha$ tunes the shape of the falloff — all learned. The result is a threshold distance wider than the Gaussian’s, so the same endpoint shift is judged “connected” more often. The Table 3 ablation also shows $f_\text{ours}$ beating the sigmoid-based form, OLS 41.4 → 44.1.
🤔 (My take) Is this really “learnable”? One thing nags at me. $\alpha, \lambda$ are indeed
nn.Parameters, but no loss or regularization is placed on them directly. Following the code, $\alpha, \lambda$ ($=$self.P, self.w) receive gradient only indirectly — distance topology → fusion → GNN → final lane loss — and even that signal is thin, since the distance branchdetaches the coordinates and the fusiondetaches the similarity. On top of that the optimizer appliesweight_decay=0.01without exempting these 1×1 scalars, so the only explicit pressure on them actually pulls toward 0. So I’d argue these parameters are closer to hyperparameters heavily governed by their initial values than to genuinely learned ones. The initializations don’t even agree between paper and code — the paper says $\alpha=0.2, \lambda=2$, while the code usesP=2, w=10(a 10× gap, if that’s the same $\alpha$).And then — after writing this, I checked OpenReview, and two NeurIPS reviewers flagged the exact same point. One suggested it would be better to “manually set the hyperparameters for a series of gradients to observe the effect on performance,” given that the learnable mapping ends up with a much higher threshold than the alternatives. The other put it more bluntly: ”$f_\text{ours}$ is just a Gaussian with an adapted decision boundary, so the fair comparison would be with a hand-tuned decision boundary.” My “isn’t this effectively a constant” suspicion had already surfaced twice in review.
So the authors did, in fact, run a sensitivity experiment in response. The rebuttal includes a table sweeping $\alpha, \lambda$ over a grid and measuring TOP$_{ll}$, and the result lays the doubt bare: moving $\alpha$ from 2.0 to 1.3 by hand alone shifts TOP$_{ll}$ by +3.5 (20.4 → 23.9), with the optimum at $\alpha=1.3, \lambda=0.23$. That value agrees with neither the paper’s stated init ($\alpha=0.2, \lambda=2$) nor the code’s ($P=2, w=10$). More decisively, what the table shows is that a hand-tuned boundary reaches the same 23.9 — not that learnable beats fixed. So the very experiment the reviewers asked for ends up, ironically, supporting the suspicion that the learnability isn’t really needed — and the authors only said it “aligns with our original results,” never that learnable scored higher. (In a separate thread they did concede the sensitivity: “TOP$_{ll}$ is sensitive to the hyperparameters.”)
Two things, then. First, this sweep table lives only in the rebuttal and never made it into the camera-ready — a reader of the paper alone can’t see this sensitivity, and the body still just says “$\alpha$ initialized to 0.2.” I suspect the authors found it awkward and left it out, but shouldn’t they at least have mentioned it? Second, the “learnable mapping function” billed as the selling point comes with zero evidence that the learnability is what beats a fixed boundary. (Honestly — sensitivity of a learnable parameter to its own initialization is table-stakes; this is a fundamentally ML venue, of all places. If I were a reviewer, I couldn’t have given a good score on this alone.) That the function form is robust to endpoint shift (Table 3) and that the parameters inside it improve by learning are two separate claims, and only the former was shown.
So the distance topology is (paper Eq. 5):
In code this mapping is one line. And to remove self-loops it multiplies by a topo_mask (= $1 - I$) that zeros the diagonal — a lane must not be considered connected to itself.
# projects/topologic/models/modules/sgnn_decoder.py — forward()
topo_mask = 1 - torch.eye(num_query, device=topo.device)
sigma = torch.std(topo)
topo = torch.exp(-torch.pow(topo, self.P) / (self.w)) * topo_mask
Let’s pin the code-to-math correspondence exactly. The paper’s $\alpha$ is the code’s self.P, and in place of the paper’s $\lambda\sigma$ the code uses a single learnable scalar self.w. Both are nn.Parameters, initialized in the decoder constructor.
# projects/topologic/models/modules/sgnn_decoder.py — __init__()
self.w = nn.Parameter(torch.tensor([10], dtype=torch.float32))
self.P = nn.Parameter(torch.tensor([2], dtype=torch.float32))
self.lamda_1 = nn.Parameter(torch.tensor([1], dtype=torch.float32))
self.lamda_2 = nn.Parameter(torch.tensor([1], dtype=torch.float32))
⚠️ A subtle gap between the math and the code. Paper Eq. 4 writes the denominator as $\lambda \cdot \sigma$, reading as if $\sigma$ (the distance matrix’s std) is multiplied in on every forward. But the actual training code (
sgnn_decoder.py) uses only a single learnable scalarself.win the denominator.sigma = torch.std(topo)is computed but never enters the exponent (it’s closer to a leftover debug line). In other words, ”$\lambda\sigma$” is absorbed into a single learned parameter $w$ in code. If you reproduce this without knowing that and multiply $\sigma$ in per the equation, your results may diverge. (My trust in this paper keeps eroding…)
② Lane Similarity Topology — alike features mean a connection
The distance approach has a clear weakness. If lane detection is wrong (the endpoint coordinates themselves are off), the distance is off too. So the authors add a second branch that looks not at coordinates but at query features — it bets on connection by how alike two lane queries are in a high-dimensional space.
The method is simple. Embed the lane query $Q_l$ through two distinct MLPs, take the inner product (matmul) for similarity, and map it into 0–1 with a sigmoid (paper Eq. 7–9).
The similarity head implements this verbatim. What’s interesting is the contrast with TopoMLP’s topology head. TopoMLP concatenated the two query embeddings and ran them through another MLP (classifier) for the logit. TopoLogic drops the concat and classifier, using the inner product of the two embeddings directly as the logit. Hence classifier sits commented out in the code.
# projects/topologic/models/dense_heads/relationship_head.py
class SingleLayerRelationshipHead(nn.Module):
def __init__(self, in_channels_o1, in_channels_o2=None, shared_param=True, ...):
self.MLP_o1 = MLP(in_channels_o1, in_channels_o1, 256, 3)
if shared_param:
self.MLP_o2 = self.MLP_o1
else:
self.MLP_o2 = MLP(in_channels_o2, in_channels_o2, 256, 3)
# self.classifier = MLP(256, 256, 1, 3) # ← unlike TopoMLP, not used
def forward(self, o1_feats, o2_feats):
o1_embeds = self.MLP_o1(o1_feats)
o2_embeds = self.MLP_o2(o2_feats)
o2_embeds = o2_embeds.permute(0, 2, 1)
relationship_pred = torch.matmul(o1_embeds, o2_embeds).unsqueeze(-1) # the inner product is the logit
return relationship_pred
So the lane–lane similarity head emits one inner-product value (logit) per $N_l \times N_l$ pair, and a sigmoid over it gives $G_\text{sim}$. (Note the class default is shared_param=True — the two inputs being the same lane query set, sharing the embedding MLP is natural — but the actual subset-A config sets shared_param=False, keeping two separate MLPs. The “default differs from config” pattern flagged in the previous post repeats here.)
③ Fusion — add the two topologies, then feed the GNN again
Now the two branches meet. Add the distance topology $G_\text{dis}$ and similarity topology $G_\text{sim}$ with learnable weights to form the final lane–lane adjacency. And — this is where it decisively parts from TopoMLP — feed that adjacency back into the next decoder layer’s GNN.
# projects/topologic/models/modules/sgnn_decoder.py — forward() (inside the decoder layer)
lclc_rel_out = lclc_branches[lid](output, output) # similarity branch (inner-product logit)
lclc_rel_adj = lclc_rel_out.squeeze(-1).sigmoid() # G_sim
prev_lclc_adj = self.lamda_1 * lclc_rel_adj.detach() + self.lamda_2 * topo # G_sim + G_dis
Here topo is the $G_\text{dis}$ from ① and lclc_rel_adj is the $G_\text{sim}$ from ②. Their weighted sum prev_lclc_adj ($\lambda_1, \lambda_2$) is the fused topology. On the loop’s next iteration this tensor enters the layer as lclc_adj=prev_lclc_adj, where the GNN (graph convolution) uses it to gather features from connected neighbor lanes and update the current lane features.
This one line distills TopoLogic’s philosophy.
- $G_\text{sim}$ carries a
.detach(). The similarity-built adjacency does refine lane features through the GNN, but the gradient of “the post-GNN result” is cut from flowing back into the similarity head. (The $G_\text{dis}$ side was already detached at the coordinates in ①, so it’s naturally cut.) - Yet both branches still receive their own loss directly. The path that refines features via fusion and the path that trains the topology itself are kept separate.
- Distance enters the graph directly. TopoNet’s SGNN estimated adjacency from learned features alone, but TopoLogic’s GNN receives the geometric signal “are the endpoints actually close” straight into the adjacency. It injects a geometric prior into graph reasoning.
📌 Training and inference fusion differ subtly. The above is the fusion inside the decoder (the training path), using the learnable
self.P / self.w / self.lamda_*. In the inference path that produces the final predictions (get_lanes()intopologic_head.py), the same fusion runs but these values are hard-coded constants —P=2, w=11.5275, lamda_1=lamda_2=1. That is, the parameters at the end of training (notably $w$ converging from its init of 10 to around 11.5275) are baked into the code. When reproducing, it’s safest to check that this hard-coding matches the trained checkpoint’s actual values. (I’ll bite my tongue here.)
# projects/topologic/models/dense_heads/topologic_head.py — get_lanes() (inference)
P, w = 2, 11.5275
lamda_1, lamda_2 = 1, 1
topo = torch.exp(-torch.pow(topo, P) / (w)) * topo_mask # G_dis (with the trained constants)
distance_topo = topo.detach().cpu().numpy()
Sim_topo = preds_dicts['all_lclc_preds'][-1].squeeze(-1).sigmoid().detach().cpu().numpy()
all_lclc_preds = lamda_1 * Sim_topo + lamda_2 * distance_topo # final lane–lane topology
④ Loss — the TopoNet lineage, unchanged
The relation loss itself is nothing new. Detection’s Hungarian matching picks the queries that hit GT, GT adjacency is laid over the pairs among them, and since connected pairs are a tiny fraction of this sparse graph, Focal Loss ($\gamma=2.0, \alpha=0.25$) tames the imbalance — the same mechanism seen in TopoNet and TopoMLP. The lane–lane loss is applied to the similarity branch’s logit (lclc_rel_out), and since an SGNN is used it is applied at every decoder layer, refining layer by layer (this differs from TopoMLP, which applied it once on the final logit, and matches TopoNet). The full flow is covered in the TopoNet post’s Topology Loss, so we skip it.
OpenLane-V2 Benchmark & Results
The benchmark and metric are the same OpenLane-V2 and OLS as the previous two posts.
This is where it matters. As flagged in the TopoMLP post, OpenLane-V2’s TOP metric was redefined once, v1.0.0 → v2.1.0, and for the same model a different version yields very different $\text{TOP}_{ll}$ numbers. The TopoLogic paper reports both versions in its table — precisely conscious of the previous post’s warning. Here are the subset-A numbers from paper Table 1.
| Method | $\text{DET}_l$ | $\text{DET}_t$ | $\text{TOP}_{ll}$ (v1.0.0) | $\text{TOP}_{ll}$ (v2.1.0) | OLS (v1.0.0) | OLS (v2.1.0) |
|---|---|---|---|---|---|---|
| TopoNet | 28.6 | 48.6 | 4.1 | 10.9 | 35.6 | 39.8 |
| TopoLogic | 29.9 | 47.2 | 18.6 | 23.9 | 41.6 | 44.1 |
How to read it:
- Detection is comparable. $\text{DET}_l$ is slightly higher at 28.6 → 29.9, but the bulk of the gap isn’t there.
- $\text{TOP}_{ll}$ explodes. 4.1 → 18.6 under v1.0.0, and 10.9 → 23.9 under v2.1.0. Detection is nearly the same, yet lane–lane topology more than doubles — the effect of absorbing endpoint shift with geometry, laid bare.
- As a result OLS rises 39.8 → 44.1 under v2.1.0. (The abstract’s “23.9 v.s. 10.9, 44.1 v.s. 39.8” is exactly these v2.1.0 figures.)
⚠️ No cross-version comparison (again). Don’t read the v1.0.0 and v2.1.0 columns of the table above mixed together. And putting the TopoMLP post’s table (mostly v1.0.0, OLS 38.2 etc.) next to this post’s v2.1.0 numbers to declare “TopoLogic is N points higher than TopoMLP” is risky too — only compare within the same version.
Aside — it lifts the score even with no training (plug-in)
TopoLogic’s most practical claim is separate. Because the geometric distance approach isn’t bound to the model architecture, it can be bolted onto another already-trained model as post-processing. With no retraining, you just add the $G_\text{dis}$ built from endpoint distances to an existing model’s topology at inference.
Paper Table 5 (and Fig. 1) shows this. Slotting geometric distance as post-processing only (+GeoDist) onto well-trained models raises $\text{TOP}_{ll}$ across the board — TopoNet 10.9 → 22.3, SMERF (SDMap) 15.4 → 26.2, LaneSegNet (lane segment) 25.4 → 29.6 — with not a single line of retraining. It’s the most direct demonstration of this paper’s view that “geometry is a free signal living outside the learned weights.”
This plug-in property resonates oddly with TopoMLP’s thesis. If TopoMLP said “detection sets the ceiling on topology,” TopoLogic adds “and by squeezing that detection output (the endpoint coordinates) once more, there’s room to raise topology further — without training.”
Conclusion — geometry into topology
To sum up, TopoLogic’s contribution is this.
A low lane–lane topology is, before reasoning, largely due to endpoint shift. So don’t leave it to learned features alone — put the geometry signal of endpoint distance directly into the topology through a learnable function, and run that back through the GNN.
If TopoNet defined the problem (end-to-end topology) and TopoMLP answered “the bottleneck is detection,” TopoLogic lifts that bottleneck one more layer to point out “the real bottleneck is that detection’s endpoints come out misaligned” and fills the gap with geometry. The picture of three papers attacking the single number $\text{TOP}_{ll}$ from different angles is now fairly sharp.
Two caveats, though. First, as seen above, there’s a gap between the math (Eq. 4’s $\lambda\sigma$) and the code (a single learnable $w$), and the training fusion (learnable) differs from the inference fusion (hard-coded constants) — check the code directly when reproducing. Second, the very strength of geometric distance makes it more sensitive to lane detection quality, a double-edged sword (which is why the similarity branch is needed as a complement).
Even so, the design — “a sum of two interpretable signals + geometry reused through the graph” — isn’t bad at all. It may not be a meticulously engineered paper, but for a field as thinly populated as lane topology reasoning, it’s a welcome drop of rain. (And the AC’s final call seems to weigh exactly that — it comes through clearly in the meta-review: a borderline paper championed less for technical depth than for being an important, much-needed contribution to a slow-moving field.)
Thanks for reading. If I’ve misunderstood anything, please let me know :)
comments