해당 글은 CV 공부를 이제 막 시작한 컴비린이가 작성한 글임을 미리 밝힙니다! 각 사진의 출처는 하이퍼링크로 달아두었습니다 :)
This post is written by the beginner who just started studying Computer Vision and i indicated references of each figure by leaving web links :)
+++ 드디어!!!! 약 5개월 만의 여정 끝에 첫 게시물을 올린다. 그동안 너무 바빠서 블로그 올릴 틈이 전혀 없었는데, 정리를 하지 않고 닥치는대로 공부하다 보니 머리에 남는게 아무 것도 없는 것 같았다. 그나마 바쁜 게 조금 덜 해진 것도 있고 하니… 앞으로는 잘 정리해서 지속적으로 포스팅 할 계획이다 ( 가끔은 개인적인 일상이나 회고록도 올릴 예정이니 많관부 ![]() )
)
U-Net: Convolutional Networks for Biomedical Image Segmentation
Authors : Olaf Ronneberger, Philipp Fischer, and Thomas Brox
Citation : About 84000 (as of 2024-05-13)
Paper Link : https://link.springer.com/chapter/10.1007/978-3-319-24574-4_28
Introduction & Related work
What is Semantic Segmentation?
Classification -> Localization -> Object Detection -> Image Segmentation
BIomedical Image Processing 뿐만이 아니라 CV 자체에 큰 임팩트를 남긴 이 논문은 Image Segmentation, 그 중에서도 Semantic Segmentation에 연관되어 있다.
그렇다면 Semantic Segmentation이란 무엇을 의미할까?
해당 논문이 투고될 2015년 당시엔 CNN의 SOTA모델이 해결할 수 있는 task는 Classification 이었다. Classification은 한 이미지가 input으로 들어가서, 단순하게 사전에 라벨링 해놓은 특정 Class로 분류되는 과정을 말한다. 즉 이미지 하나당 Output은 Labeled Class 하나이다.
( + CNN의 초기 모델 AlexNet의 Fully Connected Layer 특성을 생각해본다면 쉽게 유추할 수 있다)
여기서 한 걸음 더 나아가, Labeling 된 Class가 이미지 중에 어디에 있는지 찾는 Task가 바로 Localization이다. 주로 BBox(Bounding Box)를 찾는데, 즉 Input은 이미지이고, Output은 BBox (주로 center point의 x와 y, 그리고 bbox의 height와 width로 주어진다)로 표현된다.
Localization은 이미지 속에서 하나의 Target Single-Class 에 대해서만 찾는다. 이에 반해 사전에 Labeling한 모든 객체를 이미지속에서 찾고 각각 Localization을 진행하는게 Object Detection이다.
이 과정을 거쳐 최종적으로 발전한 단계가 바로 Image Segmentation이라고 할 수 있는데, 픽셀별로 Classification & Localization을 진행해서 특정 객체가 정확히 이미지 속에서 어디 있는지 찾는 Task이다.
아래의 그림을 보면 더 쉽게 이해할 수 있다
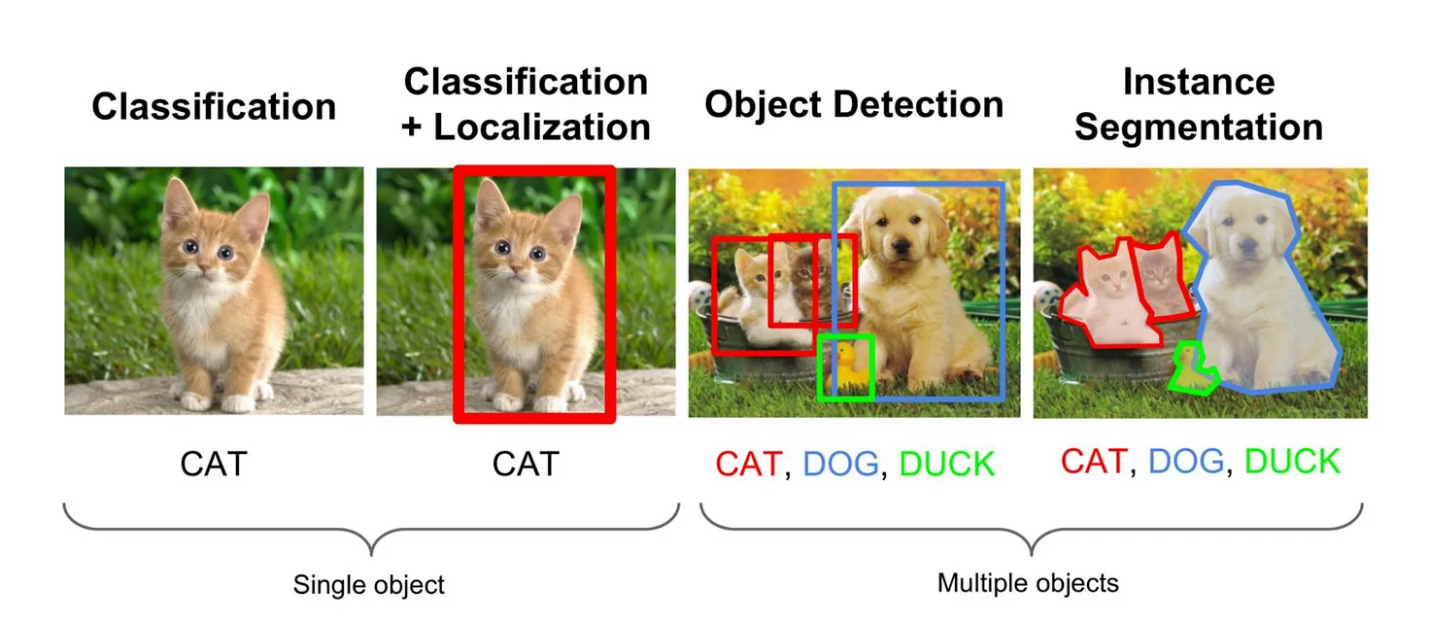
Image Segmentation
Image Segmentation은 크게 세 가지로 분류할 수 있다.
- Semantic Segmentation - 각 픽셀을 Class로 분류한다. 하지만 각각의 Instance를 구분하진 못한다. ( e.g. Car와 Person은 구분하지만 Person1 과 Person2를 구분하진 못함)
- Instance Segmentation - 각 픽셀을 Class로 분류하는 것이 아닌 Instance로 분류. 따라서 instance들이 어떤 Class에 속하는 지를 알 수 없다.
- Panoptic Segmentation - Semantic Segmentation + Instance Segmentation, 픽셀별로 어떤 Class와 Instance에 속하는지 모두 알 수 있다.
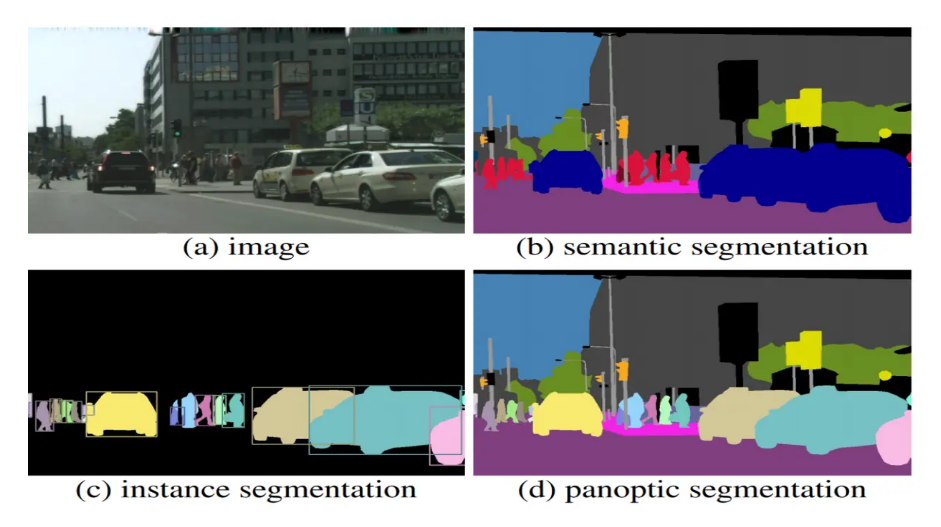
오늘 다룰 논문의 U-Net은 이 중에서도 Semantic Segmentation을 Task로 갖는다.
FC Layer vs FCN in Image Segmentation
Drawbacks of the FC Layer
Vanila CNN Architecture를 보면 FC Layer(Fully Connected Layer)가 존재한다. 이 Layer는 Classfication을 위해 존재하는데, 이름대로 어떤 레이어의 뉴런이 다음 레이어의 모든 뉴런과 연결된 구조이다. 때문에 해당 Layer에서의 Parameter는 엄청나게 많아질 수 밖에 없는데, 이는 Regularization 성능을 매우 떨어뜨릴 수 있고 학습 속도를 저하시킨다.
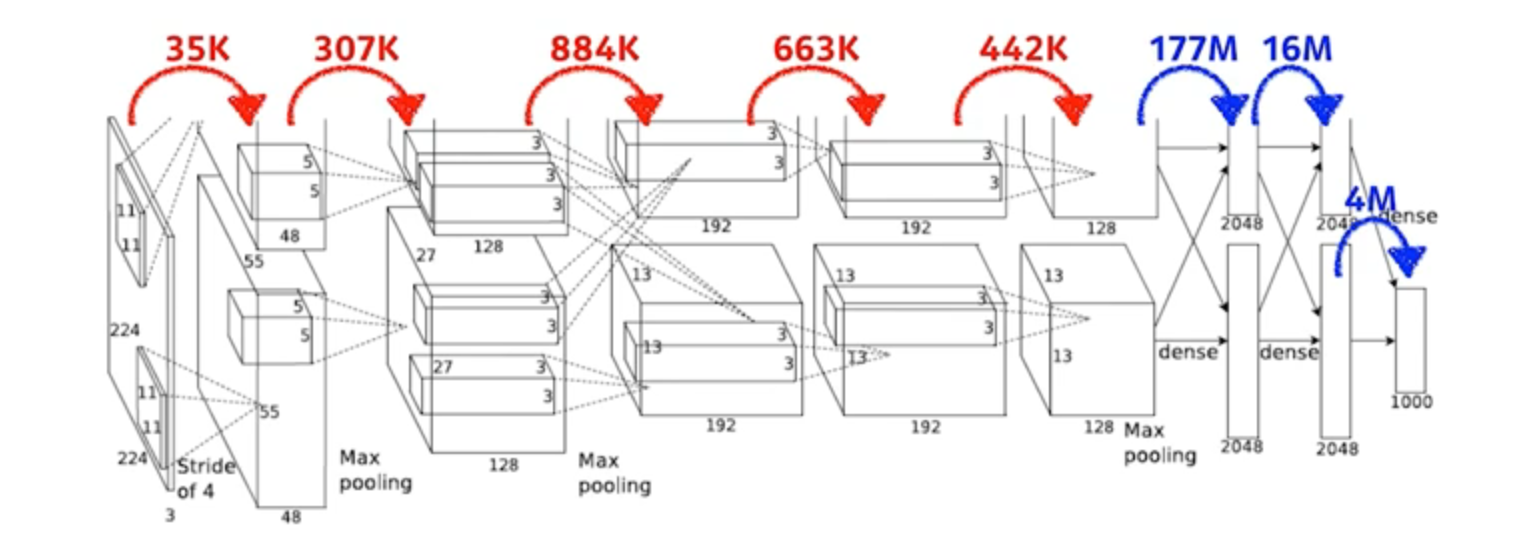
K(10^3) 단위의 Parameter 수가 FC Layer를 거치는 순간 M(10^6) 단위로 바뀌는 것을 확인할 수 있다.
또한 FC Layer의 최종 Output 채널의 차원은 Labeled Class의 개수로 유도되므로, FC Layer를 거치는 순간 공간 정보가 모두 유실된다. 이는 곧 FC Layer로는 Semantic Segmentation에서 제일 중요한 Localization을 할 수 없다는 말이 된다.
마지막으로 FC Layer의 Parameter 수는 항상 고정이기 때문에 (앞서 말한 Labeled Class 의 개수가 고정) Input Feature Map의 크기도 강제되며, 이에 따라 Input Image 크기 역시 고정된다.
FCN(Fully Convolutional Network)
기존 CNN의 구조에서 Image Segmentation을 위해 발전한 구조로, 앞서 말한 Image Segmentation 관점에서의 FC Layer의 단점을 보완하기 위해 고안되었다.
간단하게 말해서 CNN예 존재하는 FC Layer의 구조를 모두 Convolution Layer로 대체한 구조이다. 이 대체 과정을 Convolutionalization이라 한다.
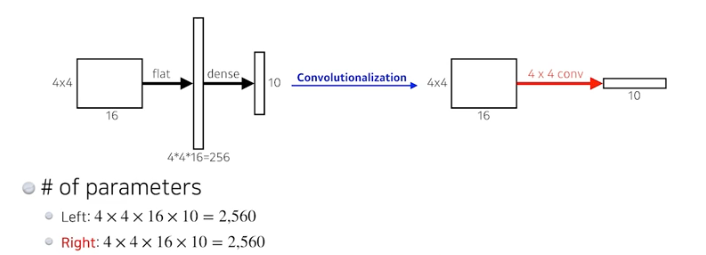
(FCN에 관한 자세한 내용은 따로 찾아보는 것을 추천)
그럼 FCN의 어떤 부분이 Image Segmentation의 관점에서 FC Layer 보다 더 뛰어날까?
이는 Convolutional Layer와 Dense Layer(FC Layer)의 특성 차이를 보면 곧 알 수 있는데, Convolutional Layer는 각 채널의 Filter SIze만큼의 Locality를 유지하기 때문에 공간 정보가 유지된다.
또한 Image Segmentation의 task 자체가 한 픽셀마다 Classification을 하는 것이다 보니, 주변 픽셀들과의 관계를 중점적으로 보는 것이 중요하다. 여기서 Dense Layer는 모든 픽셀을 전부 고려하는 반면, Convolutional Layer는 주변 픽셀들과의 관계를 학습하기 때문에 Image Segmentation에 더욱 더 적합하다.
+++ 사실 생각해보면 당연하다. 우리가 Semantic Segmentation을 통해 얻고자 하는 Output은 Pixel-Classified Image라고 볼 수 있는데, Dense Layer의 경우에는 Classification 하나의 값만 나온다.
Data Augmentation
저자는 매우 적은 Training Data를 이용했고, 그럼에도 성능이 잘 나온다고 말했다 이 이유로 Excessive Data Augmentation 을 이용했기 때문이라 밝혔는데, 이 때 Data Augmentation의 기법으로 Elastic Deformation을 사용했다고 한다.

Network Architecture
U-Shaped Network
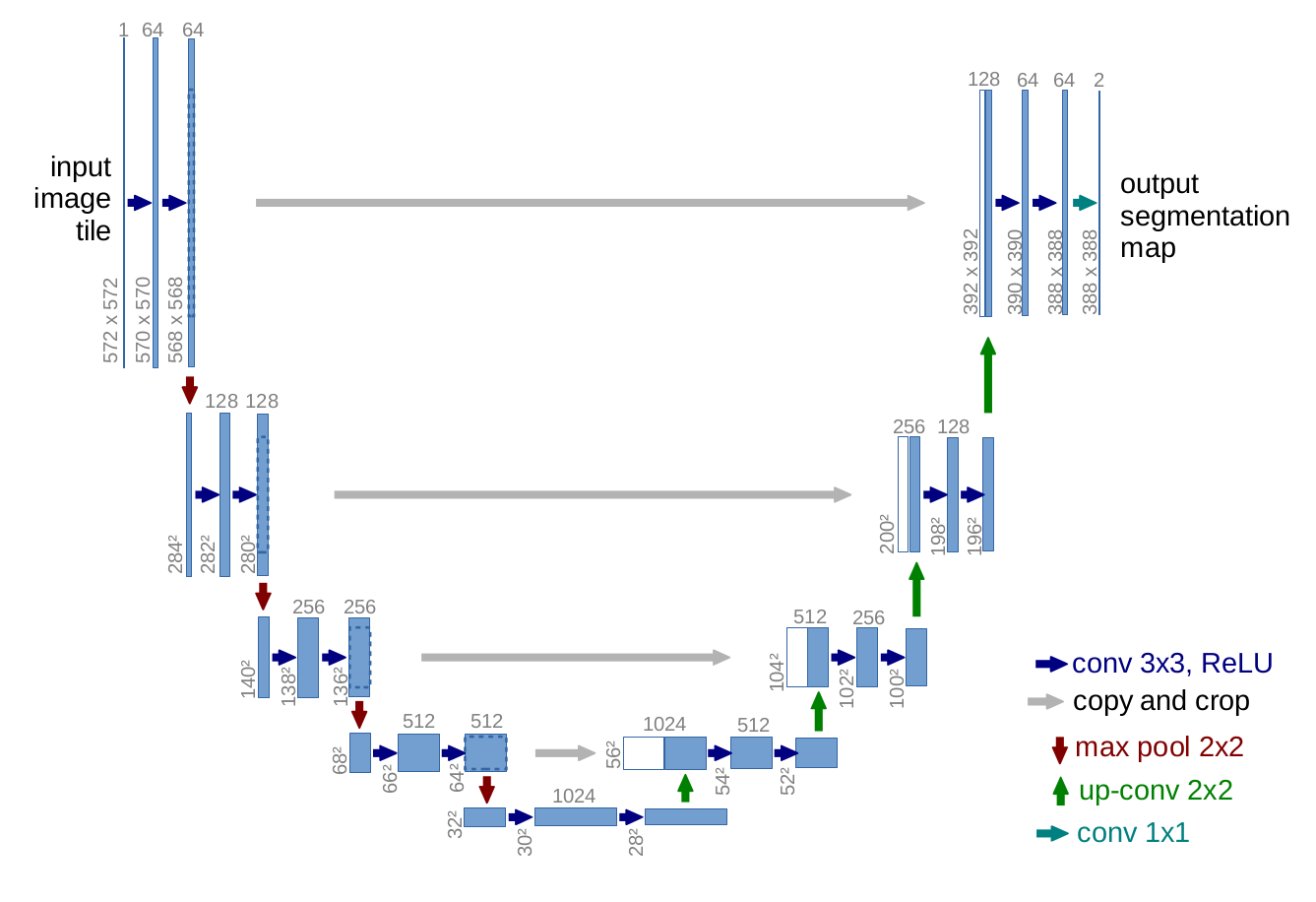
보이는 것처럼 Network가 U자 형태를 띠고 있어서 U-Net이라고 명명이 되었다.
가장 먼저 Input으로 (572,572)의 Image가 들어가게 되고, Downsampling 과정을 거치다가 Upsampling 되어 (388,388) 의 Segmentation map으로 Output이 나간다.
이 때 Downsampling 부분을 Contracting Path, Upsampling 부분을 Expanding Path 라고 한다.
Contracting Path
일반적인 CNN 과정과 동일하게 Unpadded Convolution을 2번씩 진행하며, 따라서 feature map이 (x,y) 각각 2씩 줄어드는 것을 볼 수 있다. 또한 Stride가 2인 max-pooling을 사용하여 feature map의 크기 자체를 반으로 줄인다. 이 때 pooling의 특성상 정보가 손실될 수 있는데, 이를 방지하기 위해 채널 수를 두 배로 늘려준다.
Expansive Path
Expansive Path는 (3, 3) convolution을 두 번씩, up-convolution 이라고 불리는 과정을 한 번씩, 그리고 이 과정을 반복하며 진행된다.
여기서 feature map의 크기를 복원하는 방법이 조금 특이한데, up-convolution이 되고 나서, 같은 단계에 있는 Contracting Path의 feature map을 crop해서 up-conv가 진행된 feature map에 concat시킨다. 여기서 crop을 하는 이유는 반대편에 있는 Contracting Path의 feature map의 H,W와 up-conv feature map의 H,W가 서로 일치하지 않기 때문이다.
Training
Optimizer & Hyperparameter
- Optimizer : Stochastic Gradient Descent (SGD)
- Hyperparameter : Large Batch Size, Momentum = 0.99
Energy Function
픽셀별로 Classification 을 진행할 때 Softmax를 사용했으며, 이에 따라 Energy Function은 Probabilistic Loss인 Cross Entropy로 정의된다. \(E = \sum_{\mathbf{x} \in \Omega} w(\mathbf{x}) \log(p_{\ell(\mathbf{x})}(\mathbf{x}))\)
Conclusion
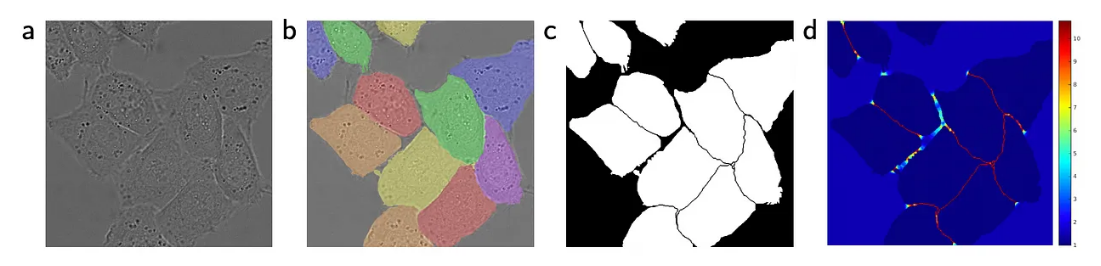
당시 Cell Segmentation 에서 가장 큰 어려움은 Cell들이 겹쳐있을 때 잘 분간하지 못한다는 점이었다. 이 부분에서 U-Net은 해당 시점의 SOTA 모델보다 더욱 잘 Segmentation을 수행했다.
저자는 마지막으로 이러한 말을 하였다.
We are sure that the u-net architecture can be applied easily to many more tasks
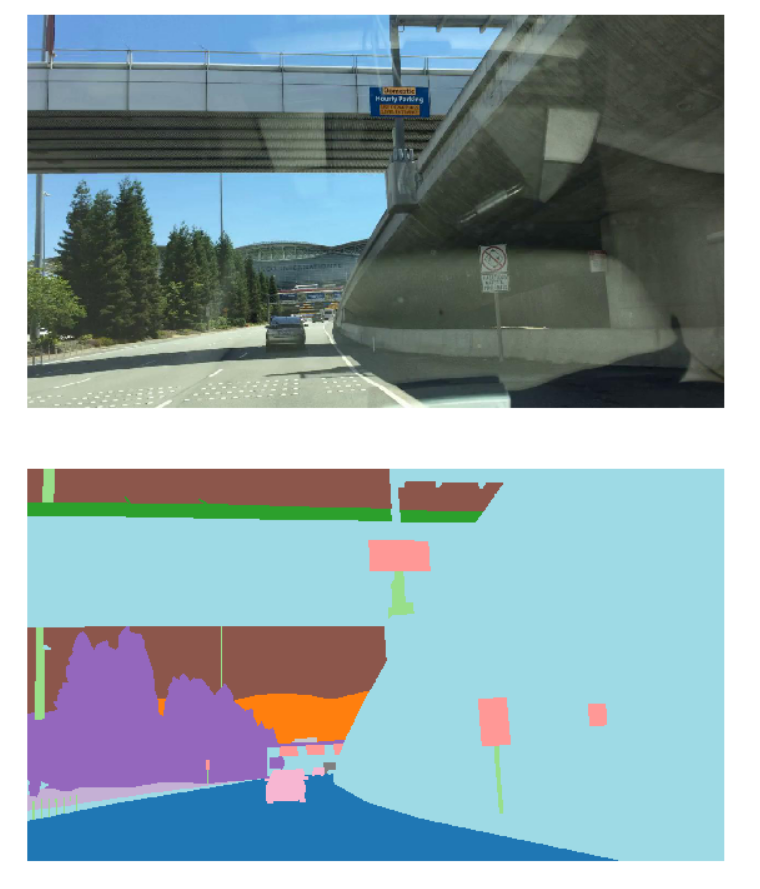
이 포스트를 작성할 시점의 2024년에 와서는, U-net은 Self-Driving Cars 분야에서도 매우 큰 영향을 미쳤다.
그의 말이 사실이 된 것이다.
Autonomous Driving에서 Semantic Segmentation은 Drivable Region과 다양한 Object들을 찾는데 중요한 역할을 한다.